Quantificar o relacionamento entre diferentes medidas nos permite usar uma medida para prever outras. Por exemplo, há uma relação entre o tamanho da nadadeira de um pinguim e o seu peso? Podemos encontrar uma resposta a essa pergunta por meio do datasetpalmerpenguins.
import pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltdf = pd.read_csv("dados/penguins_size.csv")df.head()
species 0
island 0
culmen_length_mm 2
culmen_depth_mm 2
flipper_length_mm 2
body_mass_g 2
sex 10
dtype: int64
# estatísticas descritivasdf.describe()
culmen_length_mm
culmen_depth_mm
flipper_length_mm
body_mass_g
count
342.000000
342.000000
342.000000
342.000000
mean
43.921930
17.151170
200.915205
4201.754386
std
5.459584
1.974793
14.061714
801.954536
min
32.100000
13.100000
172.000000
2700.000000
25%
39.225000
15.600000
190.000000
3550.000000
50%
44.450000
17.300000
197.000000
4050.000000
75%
48.500000
18.700000
213.000000
4750.000000
max
59.600000
21.500000
231.000000
6300.000000
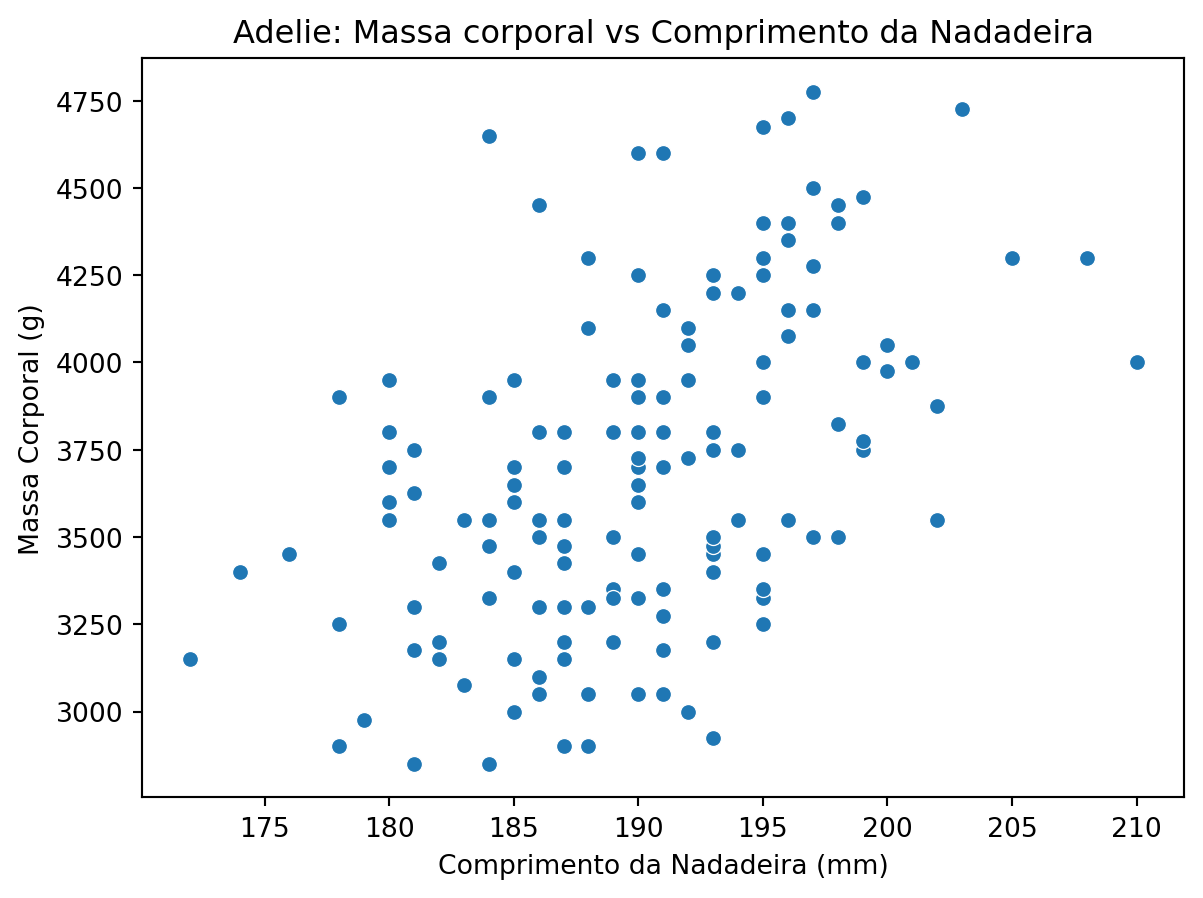
Você consegue perceber alguma relação entre o tamanho da nadadeira e o peso dos pinguins?
# filtrar apenas pinguins adelieadelie = df[df["species"] =="Adelie"]# scatter plot: massa corporal vs comprimento da nadadeirasns.scatterplot(data=adelie, x="flipper_length_mm", y="body_mass_g")plt.title("Adelie: Massa corporal vs Comprimento da Nadadeira")plt.xlabel("Comprimento da Nadadeira (mm)")plt.ylabel("Massa Corporal (g)")plt.show()
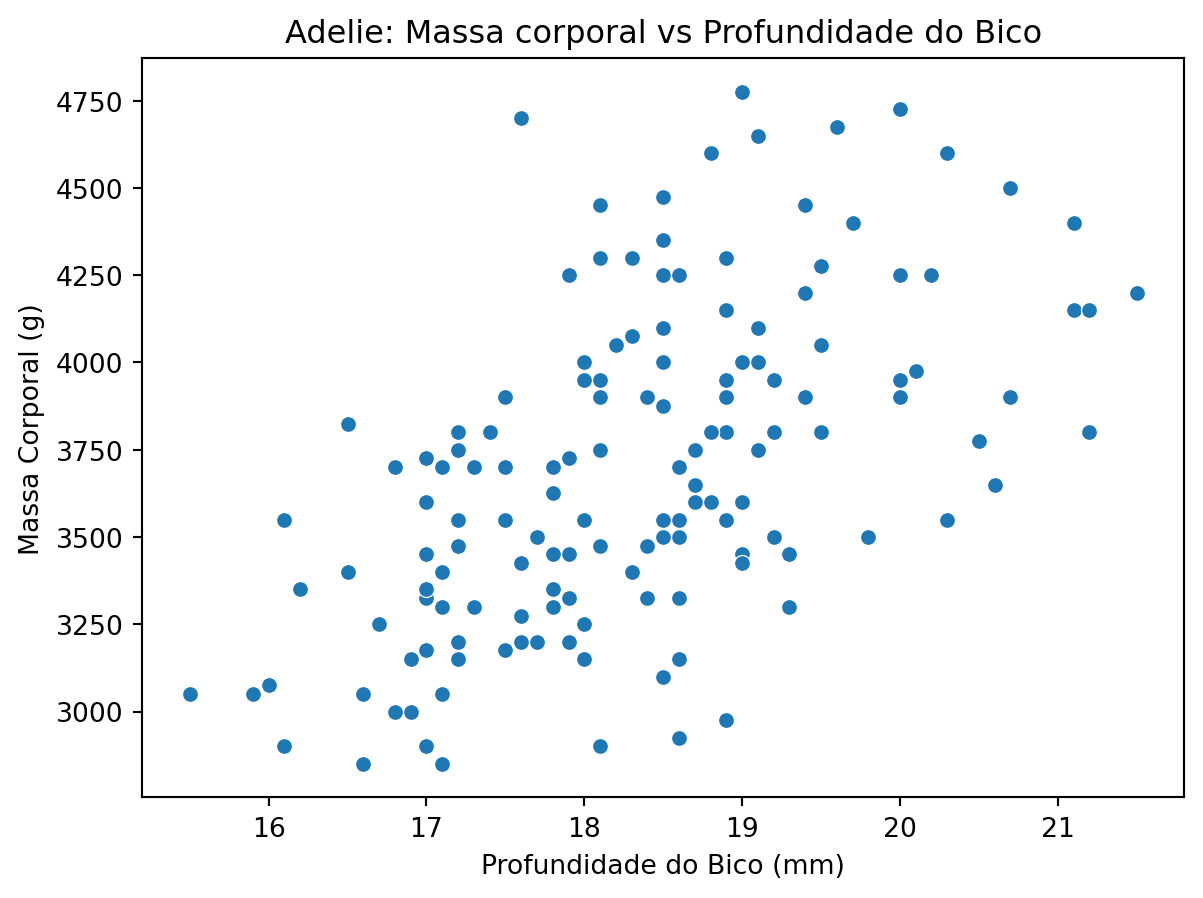
Também podemos relacionar a profundidade do bico com o peso.
Profundidade do bico
# scatter plot: massa corporal vs comprimento do bicosns.scatterplot(data=adelie, x="culmen_depth_mm", y="body_mass_g")plt.title("Adelie: Massa corporal vs Profundidade do Bico")plt.xlabel("Profundidade do Bico (mm)")plt.ylabel("Massa Corporal (g)")plt.show()
Qual das duas características tem uma relação mais forte com o peso?
Não é muito simples de responder só observando os gráficos, mas podemos calcular a correlação para quantificar essa relação.
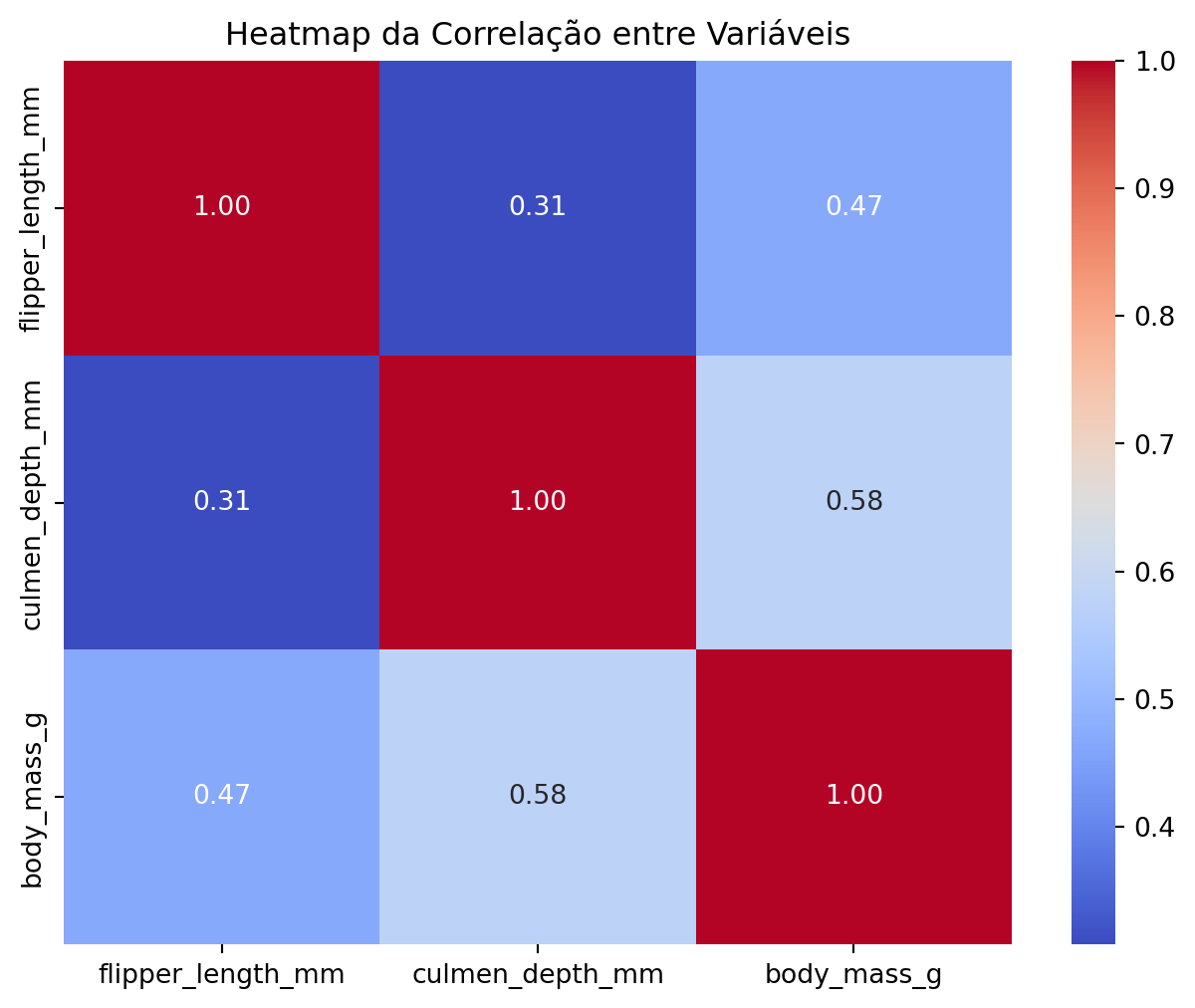
# cálculo da correlação entre as variáveiscorrelation = adelie[["flipper_length_mm", "culmen_depth_mm", "body_mass_g"]].corr()print("Correlação entre as variáveis:")print(correlation)# heatmap da correlaçãoplt.figure(figsize=(8, 6))sns.heatmap(correlation, annot=True, cmap="coolwarm", fmt=".2f")plt.title("Heatmap da Correlação entre Variáveis")plt.show()
Correlação entre as variáveis:
flipper_length_mm culmen_depth_mm body_mass_g
flipper_length_mm 1.000000 0.307620 0.468202
culmen_depth_mm 0.307620 1.000000 0.576138
body_mass_g 0.468202 0.576138 1.000000
Basicamente, quanto mais próximo de 1 ou -1, mais forte é a relação entre as duas medidas e mais parecido com uma linha é o gráfico de dispersão.
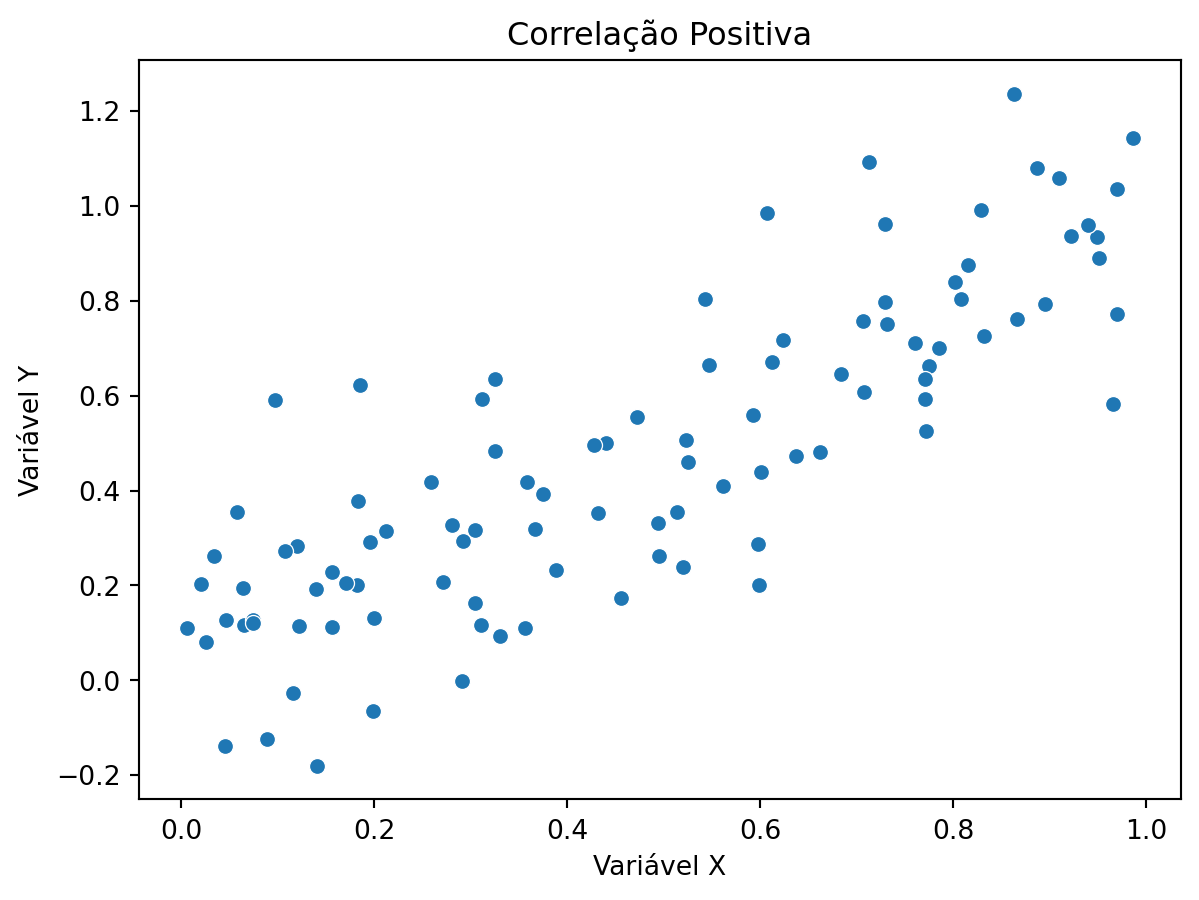
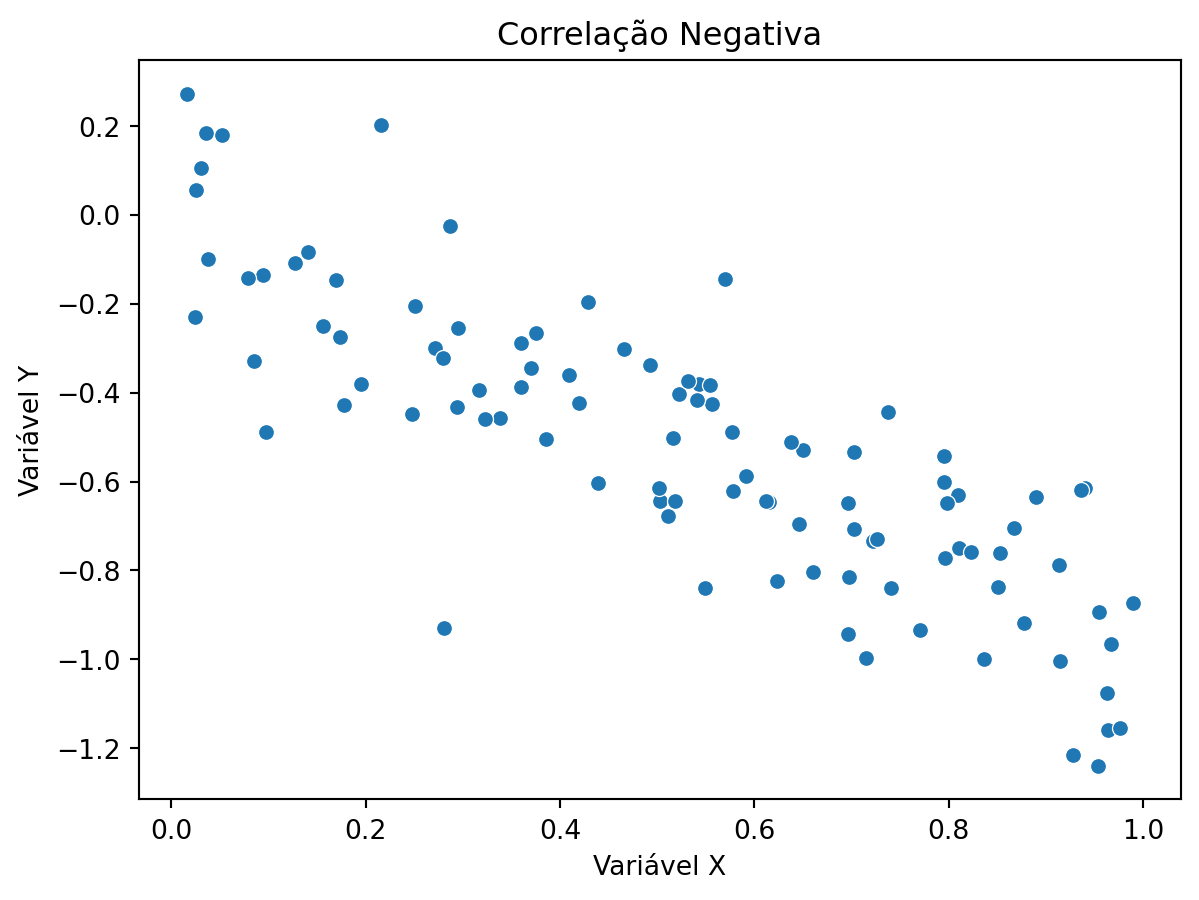
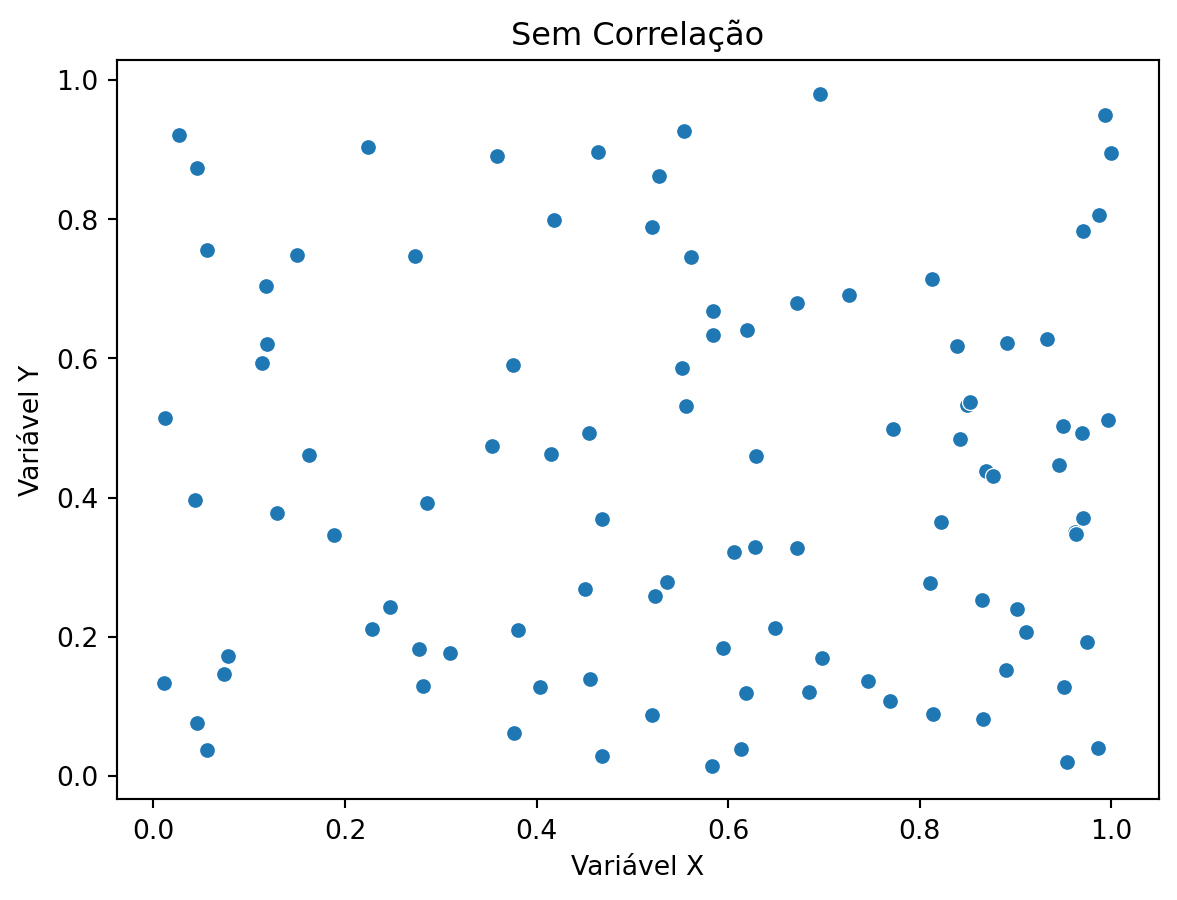
# exemplos de scatter plots com seaborn mostrando correlações diferentes com dados simulados# correlação positivaimport numpy as npnp.random.seed(42)x_pos = np.random.rand(100)y_pos = x_pos + np.random.normal(0, 0.2, 100)sns.scatterplot(x=x_pos, y=y_pos)plt.title("Correlação Positiva")plt.xlabel("Variável X")plt.ylabel("Variável Y")plt.show()# correlação negativax_neg = np.random.rand(100)y_neg =-x_neg + np.random.normal(0, 0.2, 100)sns.scatterplot(x=x_neg, y=y_neg)plt.title("Correlação Negativa")plt.xlabel("Variável X")plt.ylabel("Variável Y")plt.show()# sem correlaçãox_no_corr = np.random.rand(100)y_no_corr = np.random.rand(100)sns.scatterplot(x=x_no_corr, y=y_no_corr)plt.title("Sem Correlação")plt.xlabel("Variável X")plt.ylabel("Variável Y")plt.show()
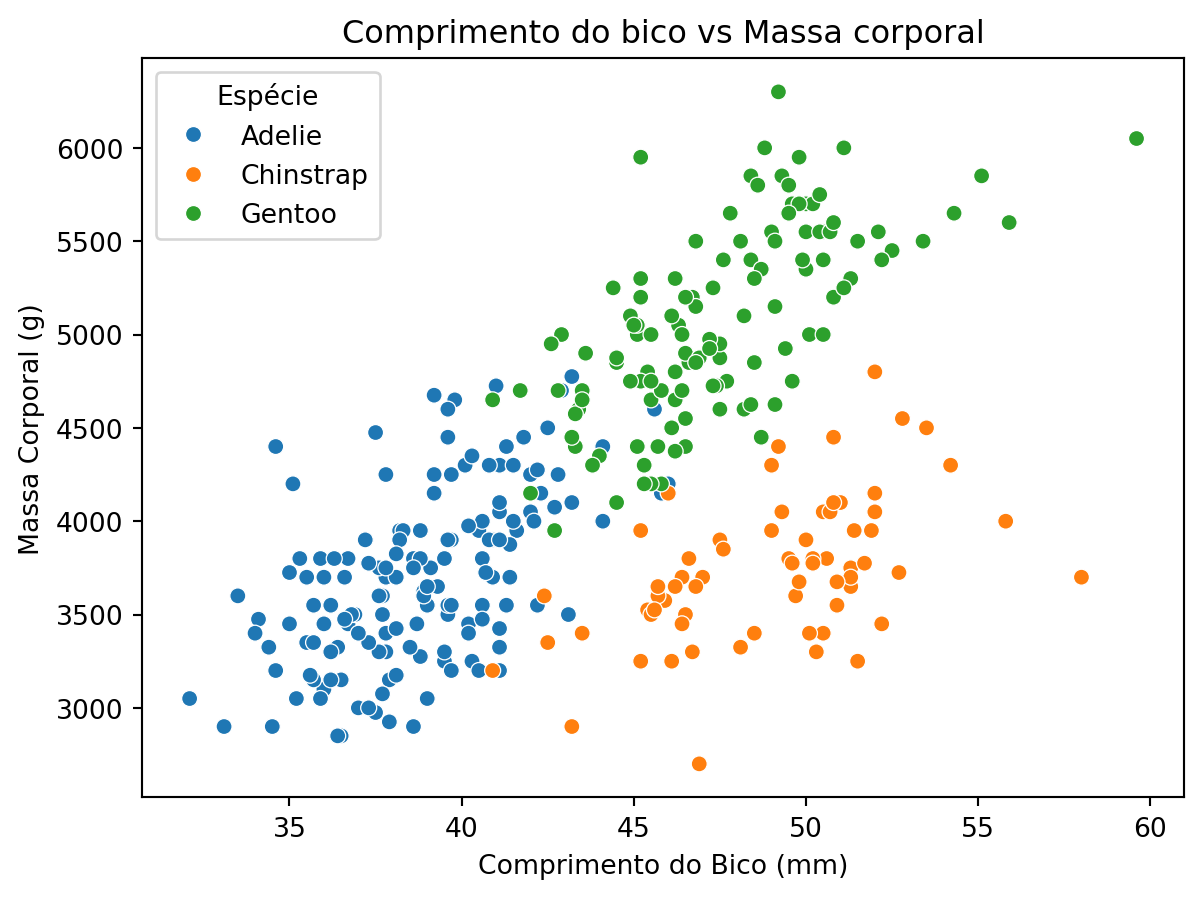
E o relacionamento das variáveis para as outras espécies de pinguins?
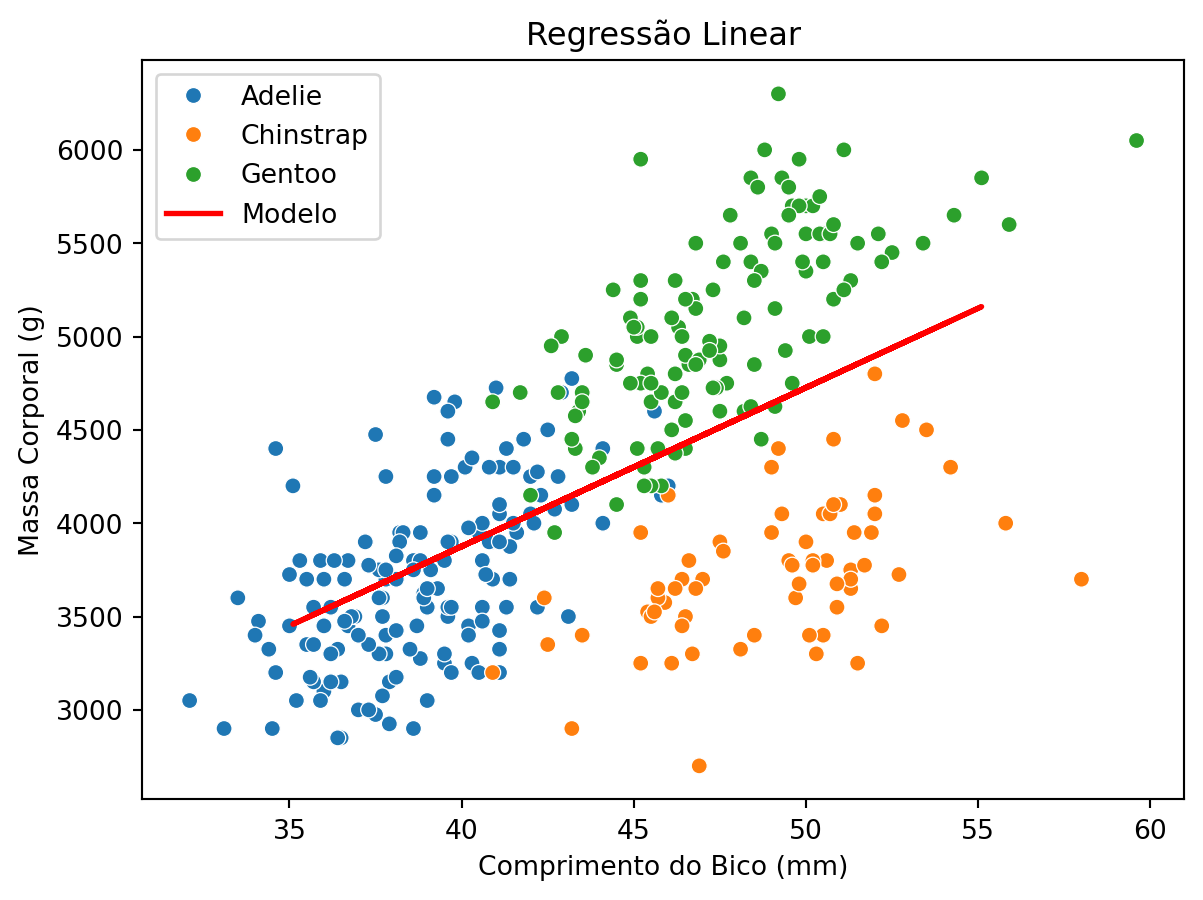
# relação entre massa corporal e comprimento do bicosns.scatterplot(data=df, x="culmen_length_mm", y="body_mass_g", hue="species")plt.title("Comprimento do bico vs Massa corporal")plt.xlabel("Comprimento do Bico (mm)")plt.ylabel("Massa Corporal (g)")plt.legend(title="Espécie")plt.show()
Regressão linear
Vamos prever a massa corporal dos pinguins com base no comprimento do bico.
from sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import train_test_split# remover valores nulosdf_reg = df[["culmen_length_mm", "body_mass_g", "species"]].dropna()# variáveis independentes e dependentesX = df_reg[["culmen_length_mm"]]y = df_reg["body_mass_g"]# separar em treino e testeX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# criar e treinar o modelomodel = LinearRegression()model.fit(X_train, y_train)# avaliação do modelor2 = model.score(X_test, y_test)print(f"Coeficiente de determinação R²: {r2:.2f}")print(f"Coeficiente angular: {model.coef_[0]:.2f}, Intercepto: {model.intercept_:.2f}")
Coeficiente de determinação R²: 0.37
Coeficiente angular: 85.06, Intercepto: 473.40